nlp_study_토큰화
텍스트 전처리는 풀고자 하는 문제의 용도에 맞게 텍스트를 사전에 처리하는 직업이다.
일반적으로 전처리되지 않은 상태의 코퍼스 데이터는 용도에 맞게 토큰화, 정제, 정규화를 하게 된다.
1. 단어 토큰화
토큰화는 주어진 코퍼스에서 토큰이라는 불리는 단위로 나누는 작업을 이른다.
-토큰화 중 생기는 선택의 순간
토큰화를 하다 보면 예상치 못한 경우가 생길 수 있다.
1) 아포스트로피의 처리
Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.
아포스트로피가 들어간 Don’t와 Jone’s를 토큰화 하는 방법?
- Don't
- Don t
- Dont
- Do n't
- Jone's
- Jone s
- Jone
- Jones
2. word_tokenize가 아포스트로피를 처리하는 방식
### 오류 발생 해결을 위한 코드
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
from nltk.tokenize import word_tokenize
from nltk.tokenize import WordPunctTokenizer
from tensorflow.keras.preprocessing.text import text_to_word_sequence
print('단어 토큰화1 :',word_tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
출력:
단어 토큰화1 : ['Do', "n't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr.', 'Jone', "'s", 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']
word_tokenize는 Don't를 Do, n't로, Jone's를 Jone, 's로 분리함.
-wordPunctTokenizer가 아포스트로피를 처리하는 방식
print('단어 토큰화2 :',WordPunctTokenizer().tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
출력:
단어 토큰화2 : ['Don', "'", 't', 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr', '.', 'Jone', "'", 's', 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']
wordPunctTokenizer는 Don't를 Don, ', t로, Jone's를 Jone, ', s 로 분리하였음.
-케라스(text_to_word_sequence)가 아포스트로피를 처리하는 방식
print('단어 토큰화3 :',text_to_word_sequence("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
출력:
단어 토큰화3 : ["don't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', 'mr', "jone's", 'orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']
모든 알파벳을 소문자로 바꾸면서 마침표나 콤마, 느낌표 등의 구두점을 제거함.
하지만 don't나 Jone's같은 경우에는 아포스트로피를 보존.
3. 토큰화에서 고려해야할 사항
i) 구두점이나 특수 문자
-마침표(문장의 경계를 아는데 도움이 되기도 하기 때문에 제거하지 않기도 함)
-단어 자체에 구두점을 가지고 있는 경우
ex) ph.D, 2002/09/10
ii) 줄임말과 단어 내에 띄어쓰기가 있는 경우
ex) we are의 줄임말인 we're, 단어 사이에 띄어쓰기가 들어간 New York
-penn TreebankTokenization
표준으로 쓰이고 있는 토큰화 방법임.
규칙1. 하이푼으로 구성된 단어는 하나로 유지
규칙2. 아포스트로피로 접어가 함께하는 단어는 분리
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "Starting a home-based restaurant may be an ideal. it doesn't have a food chain or restaurant of their own."
print('트리뱅크 워드토크나이저 :',tokenizer.tokenize(text))
출력:
트리뱅크 워드토크나이저 : ['Starting', 'a', 'home-based', 'restaurant', 'may', 'be', 'an', 'ideal.', 'it', 'does', "n't", 'have', 'a', 'food', 'chain', 'or', 'restaurant', 'of', 'their', 'own', '.']
home-based는 하나로, 아포스트로피는 구분을 한 모습.
4. 문장 토큰화
단순히 마침표나 ?, !로 구분하면 제대로 안될 수 있음
-nlkt의 문장의 토큰화를 수행하는 sent_tokenize
from nltk.tokenize import sent_tokenize
text = "I am actively looking for Ph.D. students. and you are a Ph.D student."
print('문장 토큰화2 :',sent_tokenize(text))
출력:
문장 토큰화2 : ['I am actively looking for Ph.D. students.', 'and you are a Ph.D student.']
Ph.D와 같은 단어도 잘 구분해냄.
한국어의 경우 kss가 있음.
import kss
text = '딥 러닝 자연어 처리가 재미있기는 합니다. 그런데 문제는 영어보다 한국어로 할 때 너무 어렵습니다. 이제 해보면 알걸요?'
print('한국어 문장 토큰화 :',kss.split_sentences(text))
출력:
한국어 문장 토큰화 : ['딥 러닝 자연어 처리가 재미있기는 합니다.', '그런데 문제는 영어보다 한국어로 할 때 너무 어렵습니다.', '이제 해보면 알걸요?']
5. 한국어에서의 토큰화의 어려움
한국어는 조사나 어미 등을 붙여서 말을 만드는 언어인 교착어이기 때문에 토큰화가 어렵다.
같은 단어에도 다른 조사가 붙으면 토큰화가 힘들어진다.
--> 조사를 분리해줘야한다.
형태소: 뜻을 가진 가장 작은 말의 단위
- 자립 형태소: 접사, 어미, 조사와 상관없이 자립하여 사용가능한 형태소. 체언(명, 대명, 수사)과 수식언(관형, 부사), 감탄사가 있음.
- 의존 형태소: 다른 형태소와 결합하여 사용되는 형태소. 접사, 어미, 조사, 어간이 있음.
6. 품사 태깅
단어의 표기가 같지만 품사에 따라 의미가 달라지기도 한다. 따라서 각 단어가 어떤 품사로 쓰였는지를 구분하고, 이를 품사 태깅이라 한다.
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "I am actively looking for Ph.D. students. and you are a Ph.D. student."
tokenized_sentence = word_tokenize(text)
print('단어 토큰화 :',tokenized_sentence)
print('품사 태깅 :',pos_tag(tokenized_sentence))
출력:
단어 토큰화 : ['I', 'am', 'actively', 'looking', 'for', 'Ph.D.', 'students', '.', 'and', 'you', 'are', 'a', 'Ph.D.', 'student', '.']
품사 태깅 : [('I', 'PRP'), ('am', 'VBP'), ('actively', 'RB'), ('looking', 'VBG'), ('for', 'IN'), ('Ph.D.', 'NNP'), ('students', 'NNS'), ('.', '.'), ('and', 'CC'), ('you', 'PRP'), ('are', 'VBP'), ('a', 'DT'), ('Ph.D.', 'NNP'), ('student', 'NN'), ('.', '.')]
PRP는 인칭 대명사, VBP는 동사, RB는 부사, VBG는 현재부사, IN은 전치사, NNP는 고유 명사, NNS는 복수형 명사, CC는 접속사, DT는 관사를 의미한다.
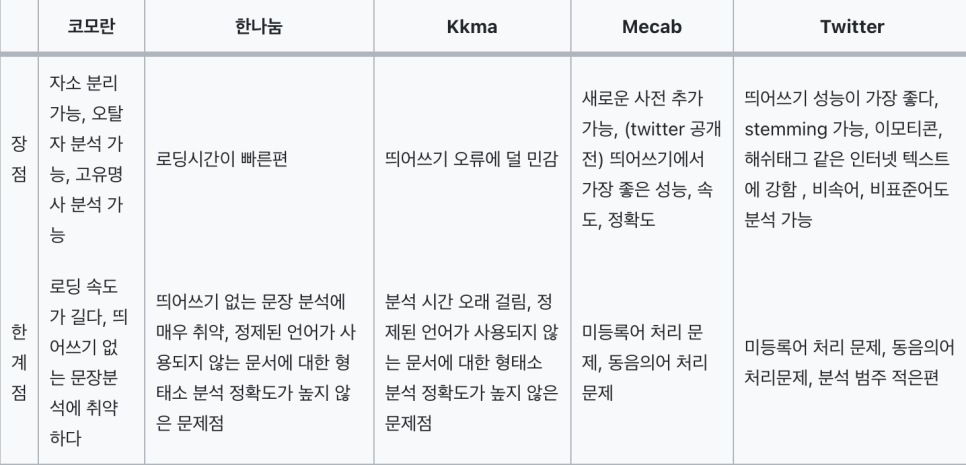
코엔엘파이를 통해서 사용할 수 있는 형태소 분석기로 Okt(Open Korea Text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma)가 있다. 전부 조금씩 성능과 결과가 다르게 나오기 때문에 용도에 따라 다른 종류의 분석기를 사용하면 된다.
(맥북에서의 오류로 실습은 진행하지 못함)
rom konlpy.tag import Okt
from konlpy.tag import Kkma
okt = Okt()
kkma = Kkma()
print('OKT 형태소 분석 :',okt.morphs("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('OKT 품사 태깅 :',okt.pos("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('OKT 명사 추출 :',okt.nouns("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
출력:
OKT 형태소 분석 : ['열심히', '코딩', '한', '당신', ',', '연휴', '에는', '여행', '을', '가봐요']
OKT 품사 태깅 : [('열심히', 'Adverb'), ('코딩', 'Noun'), ('한', 'Josa'), ('당신', 'Noun'), (',', 'Punctuation'), ('연휴', 'Noun'), ('에는', 'Josa'), ('여행', 'Noun'), ('을', 'Josa'), ('가봐요', 'Verb')]
OKT 명사 추출 : ['코딩', '당신', '연휴', '여행']
1) morphs : 형태소 추출
2) pos : 품사 태깅(Part-of-speech tagging)
3) nouns : 명사 추출